
Por Sayash Kapoor e Arvind Narayanan
O Instituto Future of Life (“Futuro da Vida”) lançou uma carta aberta pedindo uma pausa de 6 meses no treinamento de modelos linguísticos “mais poderosos que” o GPT-4. Mais de 1.000 pesquisadores, tecnólogos e figuras públicas já assinaram a carta. A carta lança o alarme sobre muitos riscos de IA:
Devemos ou não deixar que as máquinas inundem nossos canais de informação com propaganda e inverdades? Devemos ou não automatizar todos os trabalhos, inclusive aqueles que nos dão satisfação? Devemos ou não desenvolver mentes não-humanas que possam eventualmente nos ultrapassar em número, ser mais espertas que nós, tornar-nos obsoletos e nos substituir? Devemos ou não arriscar a perda do controle de nossa civilização?
Concordamos que a desinformação, o impacto sobre o trabalho e sobre a segurança são três dos principais riscos da IA. Infelizmente, em cada caso, a carta apresenta um risco especulativo, remetendo a um futuro distante, e ignora a versão do problema que já está prejudicando as pessoas. Ela desvia a atenção dos problemas reais e torna mais difícil tratá-los. A carta tem uma mentalidade de contenção análoga à do risco nuclear, mas isso é um mau enquadramento para a IA. Ela faz o jogo das empresas que busca regular.
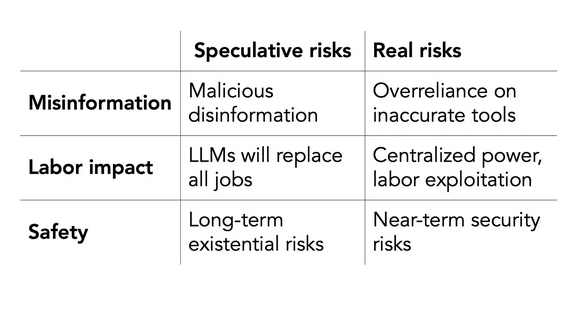
Dano especulativo 1: campanhas maliciosas de desinformação
Devemos ou não deixar que as máquinas inundem nossos canais de informação com propaganda e inverdades?
A carta se refere a uma alegação comum: os LLM [large language models, ou ”modelos de linguagem grandes“ em português] levarão a uma inundação de propaganda, pois dão a atores maliciosos as ferramentas para automatizar a criação de desinformação. Mas, como argumentamos anteriormente, criar desinformação não é suficiente para difundi-la. A distribuição da desinformação é a parte mais difícil. LLM de código aberto suficientemente poderosos para gerar desinformação também existem há algum tempo; não temos visto usos proeminentes destes LLM para disseminar desinformação.
O foco na desinformação também dá às empresas que desenvolvem LLM a justificativa perfeita para manter seus modelos guardados a sete chaves: impedir que atores maliciosos criem propaganda. Esta foi uma das razões que a OpenAI deu para o lançamento do GPT-4 ser opaco num grau sem precedentes.
Dano real 1: desinformação devido ao uso descuidado de ferramentas de IA
Em contraste, a verdadeira razão pela qual os LLM representam um risco de informação é devido à confiança excessiva e ao viés de automação. O viés de automação é a tendência das pessoas a confiar demais em sistemas automatizados. As LLMs não são treinadas para gerar a verdade; elas geram somente afirmações plausíveis. Mas os usuários podem ainda confiar nos LLM nos casos em que a precisão factual é importante.
Considere o tópico viral do Twitter sobre o cão que foi salvo porque o ChatGPT deu o diagnóstico médico correto. Neste caso, o ChatGPT foi útil. Mas não vamos ouvir falar da miríade de outros exemplos em que o ChatGPT causou mal a alguém devido a um diagnóstico incorreto. Da mesma forma, a CNET utilizou uma ferramenta automatizada para redigir 77 artigos de notícias com conselhos financeiros. Mais tarde eles encontraram erros em 41 dos 77 artigos.
Dano especulativo 2: LLMs condenarão todos os trabalhos à obsolescência
Devemos ou não automatizar todos os trabalhos, inclusive aqueles que nos dão satisfação?
O GPT-4 foi lançado com muita propaganda em torno de seu desempenho em exames humanos, tais como o “bar” [nos países de lingua inglesa, exame para admissão na associação de advogados atuantes numa determinada jurisdição] e o USMLE [exame de múltiplas etapas pelo qual o médico é obrigado a passar antes de ser autorizado a praticar medicina nos Estados Unidos]. A carta leva a sério as alegações da OpenAI: usa o artigo da OpenAI sobre o GPT-4 para citar a afirmação de que “os sistemas de IA contemporâneos estão agora se tornando competitivos, em termos humanos, nas tarefas gerais”. Mas testar LLM em avaliações projetadas para humanos nos diz pouco sobre sua utilidade no mundo real.
Este é um exemplo de sensacionalismo provocado pela crítica. A carta critica ostensivamente a implementação descuidada de LLM, mas ao mesmo tempo exagera suas capacidades e os retrata como muito mais poderosos do que realmente são. Isto, mais uma vez, ajuda as empresas ao retratá-las como criadores de ferramentas de outro mundo.
Dano real 2: as ferramentas de IA exploram força de trabalho e dão poder às empresas
O impacto real da IA provavelmente será mais sutil: as ferramentas de IA desviarão o poder dos trabalhadores e o centralizarão nas mãos de algumas poucas empresas. Um exemplo proeminente é a IA generativa para a criação de arte. Empresas que constroem ferramentas de conversão “texto-para-imagem” têm usado o trabalho de artistas sem compensação financeira ou crédito autoral. Outro exemplo: trabalhadores que filtraram o conteúdo tóxico das entradas e saídas do ChatGPT foram pagos menos de US$ 2,00 por hora.
Pausar o desenvolvimento de novas IA não faz nada para corrigir os danos de modelos já implantados. Uma maneira de fazer a coisa certa pelos artistas seria tributar as empresas de IA e usar os recursos para aumentar o financiamento para as artes. Infelizmente, falta até mesmo a vontade política de considerar tais opções. Intervenções ingênuas para aliviar a consciência, como apertar o botão de pausa, tiram a atenção desses difíceis debates políticos.
Danos especulativos 3: Riscos existenciais de longo prazo
Devemos ou não desenvolver mentes não-humanas que possam eventualmente nos ultrapassar em número, ser mais espertas que nós, tornar-nos obsoletos e nos substituir? Devemos ou não arriscar a perda do controle de nossa civilização?
Riscos catastróficos de longo prazo decorrentes da IA têm uma longa história. A ficção científica nos preparou para pensar em exterminadores e robôs assassinos. Na comunidade da IA, essas preocupações foram expressas sob o guarda-chuva do risco existencial ou risco-x, e se refletem nas preocupações da carta sobre a perda do controle sobre a civilização. Reconhecemos a necessidade de pensar sobre o impacto a longo prazo da IA. Mas estas preocupações de ficção científica sugaram o oxigênio e desviaram recursos de riscos reais e urgentes da IA — incluindo riscos de segurança.
Danos reais 3: riscos de segurança a curto prazo
A engenharia de instruções de entrada [prompt engineering] já permitiu a usuários vazar detalhes confidenciais sobre quase todos os chatbots lançados até agora. À medida que ferramentas como o ChatGPT forem integradas com aplicações do mundo real, estes riscos de segurança se tornam mais danosos. Assistentes pessoais baseados em LLM podem ser invadidos para revelar dados das pessoas, engajar-se em ações prejudiciais no mundo real (como desligar sistemas) ou até mesmo dar origem a worms [tipo de programa malicioso] que se espalham pela internet por meio de LLM. Mais importante ainda, estes riscos de segurança não exigem um salto nas capacidades dos modelos — os modelos já existentes são vulneráveis a eles.
A abordagem dos riscos de segurança exigirá colaboração e cooperação com o meio acadêmico. Infelizmente, a propaganda nesta carta — o exagero das capacidades e o risco existencial — provavelmente levará a que os modelos sejam fechados com ainda maior ênfase, dificultando ainda mais a abordagem dos riscos.
A mentalidade de contenção é um mau enquadramento para a IA generativa
A carta posiciona o risco da IA como análogo ao risco nuclear, ou ao risco da clonagem humana. Ela defende pausar o desenvolvimento das ferramentas de IA porque outras tecnologias catastróficas já foram pausadas antes. Mas é pouco provável que uma abordagem de contenção seja eficaz para a IA. As LLM são muitíssimo mais baratas de construir que as armas nucleares ou a clonagem — e o custo está caindo rapidamente. Além disso, o know-how técnico para construir LLM já está difundido.
Embora não seja bem compreendido fora da comunidade técnica, nos últimos 6 meses, houve uma grande mudança na pesquisa e comercialização de LLM. Os aumentos no tamanho do modelo não são mais o principal motor do aumento da utilidade e das capacidades. A ação passou a ser o encadeamento e conexão dos LLM ao mundo real. Novas capacidades e riscos surgirão principalmente dos milhares de aplicativos nos quais LLM estão sendo incorporados neste momento — e também nos plugins sendo incorporados no ChatGPT e outros chatbots.
Outra grande tendência tecnológica em LLM é a compressão. Os LLM estão sendo otimizados para funcionar localmente em dispositivos móveis. Um modelo de 4GB baseado na LLaMA LLM da Meta pode rodar em um Macbook Air 2020. As capacidades deste modelo estão na mesma classe do GPT-3, e, é claro, ele está sendo conectado a outras aplicações. Conter tais modelos é trabalho inútil, pois são fáceis de distribuir e podem rodar em hardware de usuário final.
Uma estrutura melhor para regular os riscos da integração de LLM em aplicações é a segurança do produto e a proteção do consumidor. Os danos e as intervenções serão muito diferentes entre aplicações: busca, assistentes pessoais, aplicações médicas, etc.
A mitigação dos riscos de IA é importante. Mas igualmente importante é considerar quais são esses riscos. Soluções ingênuas, como amplas moratórias, desviam os debates políticos sérios em favor dos sonhos de febre sobre a IAG, e são, em última análise, contraproducentes. Chegou a hora de aprimorar nossa análise.
Sayash Kapoor é doutorando no Centro de Política da Tecnologia da Informação da Universidade de Princeton.
Arvind Narayanan é professor do Departamento de Ciência da Computação da Universidade de Princeton, onde lidera o Projeto Princeton pela Transparência e Responsabilidade na Web.
Traduzido pelo Passa Palavra a partir do original publicado pelos autores em 29 de março de 2023 em seu blog AI Snake Oil.
A arte em destaque é da autoria de Jean Tinguely (1925-1991).

")
")
")

O que está acontecendo hoje é que algumas pessoas mto jovens tomam o ChatGPT como verdade absoluta.
Fazem uma pergunta e ali ele apresenta A Verdade. Referencial bibliografico só é valido o que estiver ali e por aí vai.
Enfim, complicado.